slam技术,即同步定位与地图构建(Simultaneous Localization and Mapping),是机器人学、计算机视觉和自动化领域的一项核心技术,其核心目标是在未知环境中,让移动机器人或智能设备同时完成自身位置的确定(定位)和环境地图的构建(地图构建),这项技术的突破性意义在于,它使得机器人摆脱了对预先部署基础设施或外部定位设备(如GPS信号)的依赖,能够在完全未知或动态变化的环境中实现自主导航与交互,slam技术解决了机器人在“陌生地方”的“我是谁”(定位)和“我在哪”(地图构建)两大核心问题,是实现机器人自主移动、操作和智能交互的基础。
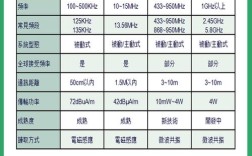
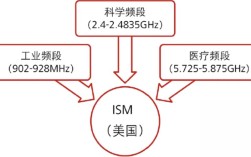
从技术本质上看,slam是一个典型的状态估计问题,其核心挑战在于“鸡生蛋还是蛋生鸡”的矛盾:机器人的位置信息需要地图来估计,而地图的构建又依赖于机器人的位置信息,为了解决这一矛盾,slam系统通常通过传感器数据采集、状态估计、数据关联和地图更新等步骤循环迭代,逐步优化机器人的位姿(位置和姿态)和环境地图,根据传感器类型的不同,slam技术主要可分为视觉slam(v-slam)、激光slam(l-slam)以及多传感器融合slam三大类,激光slam通过激光雷达(lidar)获取环境的三维点云数据,具有精度高、距离测量准确的优势,尤其在结构化环境中表现优异,但其成本较高且易受光照和纹理变化影响;视觉slam则利用摄像头捕获的图像或视频序列,通过特征提取、匹配和位姿估计实现定位与建图,成本低、信息丰富,但对光照变化、纹理缺失和运动模糊等场景较为敏感;多传感器融合slam则结合激光、视觉、惯性测量单元(imu)、轮式编码器等多种传感器的数据,通过卡尔曼滤波、粒子滤波或优化算法(如因子图优化)实现优势互补,显著提升系统的鲁棒性和精度。
一个完整的slam系统通常包含前端数据关联、后端优化、回环检测和地图管理四个关键模块,前端模块负责处理传感器数据,通过特征匹配或直接法估计相邻时刻机器人的相对位姿,建立初步的位姿图;后端模块则以前端结果为观测值,通过非线性优化算法(如g2o、ceres solver)最小化重投影误差或点云匹配误差,优化全局位姿和地图参数,解决累积误差问题;回环检测模块通过识别已访问区域,检测到闭环时通过位姿图优化消除累积误差,提升地图的一致性;地图管理模块则根据应用需求选择地图表示形式(如栅格地图、拓扑地图、点云地图或语义地图),并实现地图的更新、维护与持久化存储,在激光slam中,前端通过迭代最近点(icp)算法匹配相邻点云帧估计位姿,后端通过因子图优化优化全局位姿,回环检测则通过点云特征匹配识别闭环;而在视觉slam中,前端提取orb、sift等图像特征进行匹配,后端通过bundle adjustment(ba)优化三维点和相机位姿,回环检测则通过词袋模型(bag of words)快速匹配图像场景。
slam技术的应用场景极为广泛,涵盖了消费电子、自动驾驶、机器人、增强现实(ar)与虚拟现实(vr)等多个领域,在消费电子领域,智能手机中的ar应用(如pokemon go)、扫地机器人(如irobot roomba)的自主导航都依赖slam技术实现定位和地图构建;在自动驾驶领域,slam是车辆在高精度地图辅助下实现车道级定位、环境感知和路径规划的核心技术,尤其在gps信号丢失的隧道、地下停车场等场景中不可或缺;在服务机器人领域,slam使导览机器人、物流机器人能够在复杂室内环境中自主移动和避障;在ar/vr领域,slam通过实时构建用户周围的三维环境地图,实现虚拟物体与真实场景的精准融合,提升沉浸式体验,dji的无人机通过视觉slam实现无gps环境下的精准悬停,波士顿动力的spot机器人通过激光slam和视觉融合实现复杂地形下的自主导航,而微软的hololens则通过slam技术将虚拟信息叠加到真实世界中。
尽管slam技术取得了显著进展,但仍面临诸多挑战,动态环境是slam的主要难题之一,环境中移动物体(如行人、车辆)会导致传感器数据出现异常,影响定位和建图精度;弱纹理或重复纹理环境(如白墙、走廊)会导致特征提取困难,引发数据关联失败;大规模环境下的实时性要求也对算法效率和计算资源提出更高需求;传感器噪声、尺度不确定性(视觉slam中难以确定地图真实尺度)以及多传感器时间同步等问题也制约着slam系统的鲁棒性,为解决这些问题,研究人员提出了多种改进方法:基于语义分割的动态slam通过识别和剔除动态物体点云或图像特征,提升静态环境建模精度;直接法slam(如dso、vins-mono)不依赖特征提取,适用于弱纹理环境;多传感器融合slam通过imu数据提供高频运动预测,弥补视觉或激光数据的采样延迟;而基于深度学习的slam(如orb-slam3与神经网络结合)则通过场景理解、特征增强或端到端优化进一步提升性能,vins-fusion通过融合视觉和imu数据,实现了高精度鲁棒的实时定位;loam(lidar odometry and mapping)及其改进算法(le-loam、fast-lio)则通过优化点云匹配效率,实现了大规模环境下的快速建图。
slam技术将朝着更高精度、更强鲁棒性、更低成本和智能化方向发展,随着传感器性能的提升(如固态激光雷达、事件相机)和计算平台的发展(如边缘计算芯片、gpu加速),slam系统将实现更高分辨率的地图构建和更低延迟的实时定位;人工智能与slam的深度融合将成为趋势,通过深度学习实现场景语义理解、动态目标预测和自主决策,使slam系统从几何感知向语义感知升级,slam与强化学习、路径规划、目标识别等技术的结合,将推动机器人从“被动导航”向“主动交互”进化,在智能家居、智慧城市、元宇宙等场景中发挥更大作用。
相关问答FAQs
Q1:slam技术与传统导航定位(如gps)有何本质区别?
A:slam技术与传统gps定位的核心区别在于工作环境和依赖条件,gps依赖卫星信号实现全球定位,但在室内、隧道、水下等无信号场景中完全失效,且定位精度易受多径效应、大气干扰影响;而slam通过自身传感器(激光、视觉等)在未知环境中自主构建地图并定位,无需外部基础设施,适用于无gps的复杂环境,gps提供的是绝对坐标定位,而slam在无先验地图时只能实现相对定位,需通过回环检测等手段消除累积误差以获得全局一致性。
Q2:为什么视觉slam在弱纹理环境中表现较差?如何改进?
A:视觉slam依赖图像特征(如角点、边缘)进行数据关联和位姿估计,弱纹理环境(如白墙、玻璃幕墙)缺乏显著特征,导致特征提取困难、匹配失败,进而引发位姿估计漂移或发散,改进方法包括:①采用直接法slam(如dso),通过像素灰度值梯度直接优化位姿,不依赖特征提取;②融合imu数据提供高频运动先验,弥补视觉数据不足;③引入结构光或ToF传感器辅助深度信息获取,增强环境几何约束;④基于深度学习的特征增强网络,通过合成特征或语义分割提升弱纹理区域的特征可检测性。