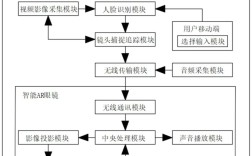
语音识别技术历史发展
语音识别技术,即让机器能够“听懂”并转写人类语言的技术,其发展史是一部融合了信号处理、声学、语言学、计算机科学和人工智能的跨学科史诗,它的发展并非一蹴而就,而是经历了多次从“热潮”到“低谷”的螺旋式上升过程。

(图片来源网络,侵删)
第一阶段:萌芽与理论基础 (1950s - 1970s)
这个时期是语音识别的“石器时代”,主要目标是实现特定说话人、有限词汇的识别。
- 核心思想: 模仿人耳的听觉机制,通过提取声音的声学特征,并与预先存储的模板进行匹配。
- 关键技术: 模板匹配。
- 机器将每个词汇(如“数字0-9”)录制下来,形成一个“声音模板库”。
- 当输入一个语音信号时,系统会将其切分成小片段,计算每个片段的特征(如能量、过零率等),然后与模板库中的所有片段进行比对,选择最相似的那个作为识别结果。
- 标志性事件:
- 1952年:贝尔实验室的Davis等人开发了第一个能识别10个英文数字的特定说话人系统,这是语音识别领域公认的第一个里程碑。
- 1960s: 出现了动态时间规整算法,这是一个巨大的进步,因为它解决了不同人说话速度不同的问题,使得系统能够对齐不同长度的语音信号进行匹配。
- 局限性:
- 特定说话人: 必须由录制模板的人来使用,否则识别率极低。
- 小词汇量: 只能识别几十个孤立的词汇。
- 孤立词识别: 说话时必须在每个词之间有明显停顿,无法识别连续的句子。
- 对环境噪声和口音非常敏感。
第二阶段:统计建模与初步繁荣 (1980s - 1990s)
这个时期,语音识别从“模板匹配”转向了更强大的统计建模方法,性能得到显著提升,并催生了商业化的萌芽。
- 核心思想: 不再依赖固定的模板,而是从大量数据中学习语音和文字之间的统计规律。
- 关键技术:
- 隐马尔可夫模型:这是本世纪最重要的技术突破。
- HMM将语音看作一个生成过程,它假设每个音素(构成语音的最小单位)对应一个隐藏的“状态”,而听到的声音信号是这些状态随机产生的“观测值”。
- 通过训练,HMM可以学习到每个音素对应的声学特征分布,识别时,系统通过寻找一条最可能的“状态转移路径”,来解码出对应的音素序列,最终形成单词和句子。
- HMM的强大之处在于它能够很好地建模语音的时间动态性和变异性,对说话人、语速变化有更好的鲁棒性。
- 统计语言模型:为了解决词序问题,研究者引入了N-gram模型,它通过统计大量文本中相邻词组出现的频率,来预测一个句子出现的概率。“我爱”后面接“中国”的概率,远大于接“桌子”的概率,这极大地帮助了系统在多个候选结果中选择最通顺、最合理的句子。
- 隐马尔可夫模型:这是本世纪最重要的技术突破。
- 标志性事件:
- 1988年: 卡内基梅隆大学的李开复博士开发了SPHINX系统,首次成功地将HMM和N-gram模型结合,实现了大词汇量、连续语音识别,这是从“能听词”到“能听句”的飞跃。
- 商业化尝试: 出现了如Dragon Systems(后被Nuance收购)等公司,推出了面向消费者的听写软件,如Dragon NaturallySpeaking。
- 局限性:
- 仍然需要大量人工标注数据进行训练。
- 对计算资源要求很高。
- 识别率在真实场景(如电话、会议)下表现不佳,远未达到实用水平。
第三阶段:机器学习与混合系统时代 (2000s - 2010s初)
进入21世纪,机器学习,特别是高斯混合模型-隐马尔可夫模型的混合架构,成为主流,语音识别的应用开始向移动设备渗透。
- 核心思想: 用更复杂的机器学习模型(GMM)来替代HMM中简单的声学模型,以更精细地描述声学特征的概率分布。
- 关键技术:
- GMM-HMM混合模型: HMM负责建模语音的时序结构,而GMM负责在每个HMM状态下,对声学特征向量进行更精确的概率建模,这成为此后近十年工业界和学术界的事实标准。
- 深度学习萌芽: 研究者开始尝试用神经网络来替代GMM,但此时神经网络通常只作为HMM的一个特征提取器或声学模型的一部分,整个系统仍然是混合架构。
- 标志性事件:
- 2009年: Google推出了基于搜索的语音搜索服务,让语音识别首次被亿万普通用户大规模使用,虽然其底层仍是GMM-HMM,但通过海量数据和强大的服务器,用户体验得到了质的飞跃。
- 移动端语音助手: Apple在2011年推出Siri,Google在2012年推出Google Now,标志着语音识别正式成为人机交互的重要入口,这些系统集成了语音识别、自然语言处理和知识图谱,功能远超单纯的转写。
第四阶段:深度学习革命 (2010s中 - 至今)
这是语音识别发展史上最激动人心的阶段。深度学习的引入彻底颠覆了传统方法,将识别性能提升到了前所未有的高度。

(图片来源网络,侵删)
- 核心思想: 使用深度神经网络直接从原始声学特征中学习到高级的、抽象的表示,并直接输出音素或文字,绕过了复杂的HMM结构。
- 关键技术:
- 端到端模型: 这是革命性的范式转变,传统方法是一个“管道”(Pipeline):声学特征 -> HMM -> 音素 -> 词典 -> 句子,端到端模型则直接从语音波形映射到文字序列,减少了信息损失和误差累积。
- 关键模型架构:
- 深度神经网络-隐马尔可夫模型:这是过渡性的里程碑,用深度神经网络(如DNN)完全取代了GMM,作为HMM的声学模型,性能相比GMM-HMM有巨大提升。
- CTC (Connectionist Temporal Classification, 连接时序分类):允许模型直接输出变长的标签序列,无需预先对齐,非常适合端到端训练。
- RNN-T (Recurrent Neural Network Transducer, 循环神经网络转导器):结合了RNN处理序列的能力和CTC的解码方式,是目前工业界最主流的端到端模型之一,被Google、Amazon等广泛使用。
- Transformer/Attention模型:受自然语言处理领域成功启发,基于注意力机制的模型(如Conformer)成为当前最先进的模型,它们能更好地捕捉长距离依赖关系,计算效率更高,并行化程度更好,已成为语音识别领域的新王者。
- 标志性事件:
- 2025年: 微软研究人员在Switchboard标准测试集上,首次将词错误率降低到了人类速记员的水平(约5.9%),宣告了深度学习在语音识别领域的全面胜利。
- 云服务与普及: Google Cloud Speech-to-Text, Amazon Transcribe, Azure Speech Services等云服务让企业可以轻松集成顶尖的语音识别能力。
- 多模态融合: 结合视觉信息(如唇语)的语音识别,在嘈杂环境下表现更佳。
- 个性化与自适应: 系统能够快速适应用户的口音、语速和用词习惯,提供更个性化的体验。
总结与展望
| 时期 | 核心思想 | 关键技术 | 标志性成就 |
|---|---|---|---|
| 1950s-1970s | 模仿人耳,模板匹配 | DTW算法 | 第一个特定说话人数字识别系统 |
| 1980s-1990s | 统计建模,学习规律 | HMM, N-gram, SPHINX系统 | 大词汇量连续语音识别,商业化起步 |
| 2000s-2010s初 | 机器学习优化 | GMM-HMM, 搜索技术 | Google语音搜索,Apple Siri,移动端普及 |
| 2010s中-至今 | 深度学习,端到端 | DNN-HMM, CTC, RNN-T, Transformer | 词错误率超越人类,云服务普及,多模态融合 |
未来展望:
- 极致的低资源场景: 如何在方言、小语种或数据极少的情况下实现高精度识别。
- 情感与意图理解: 不仅是“听清”,更要“听懂”,理解说话人的情绪、态度和深层意图。
- 多模态融合: 结合视觉(唇读、表情)、生理信号(脑电、心率)等多模态信息,构建更鲁棒、更自然的交互系统。
- 实时性与边缘计算: 将模型轻量化,直接在手机、汽车、智能家居等终端设备上运行,保护隐私,降低延迟。
- 对话式AI: 语音识别将与自然语言理解、对话管理、语音合成等技术深度融合,成为真正能与人类进行开放式、多轮对话的智能体。
语音识别技术已经从一个实验室里的新奇玩意,演变成了驱动数字世界运转的核心基础设施之一,它的历史,就是一部不断追求更自然、更高效的人机交互的奋斗史。

(图片来源网络,侵删)