第一部分:数据采集技术
数据采集技术是手段,决定了你能拿到什么数据、以什么质量拿到,主要可以从采集对象、采集方式和数据类型三个维度来划分。

(图片来源网络,侵删)
按采集对象划分
这是最直观的分类方式,直接关系到数据源。
a. 互联网数据
- 技术手段:
- 网络爬虫: 最核心的技术,使用 Python 的
Scrapy,BeautifulSoup,Selenium等库,模拟浏览器行为,抓取网页上的文本、图片、链接等。 - API 接口: 很多网站(如社交媒体、电商平台)提供官方 API,是获取结构化数据最稳定、最合规的方式,Twitter API, OpenAI API。
- 日志文件: 服务器访问日志、应用运行日志等,是分析用户行为和系统性能的重要数据源。
- RSS/Atom 订阅源: 用于获取新闻、博客等内容的更新。
- 网络爬虫: 最核心的技术,使用 Python 的
- 特点: 数据量大、更新快、非结构化或半结构化多、需注意法律和道德风险(如
robots.txt协议)。
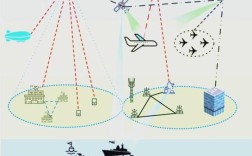
b. 物理世界数据
- 技术手段:
- 传感器技术: 这是物联网的核心。
- 温湿度传感器: 环境监测。
- 摄像头/图像传感器: 视频监控、人脸识别、工业质检。
- 麦克风/声学传感器: 语音识别、噪音监测。
- GPS/北斗模块: 位置信息。
- 加速度计/陀螺仪: 运动姿态感知(手机、可穿戴设备)。
- RFID/NFC: 身份识别、物流追踪。
- 智能电表/水表: 自动采集公用事业数据。
- 传感器技术: 这是物联网的核心。
- 特点: 数据实时性强、与物理世界直接关联、多为时间序列数据。
c. 业务系统数据

(图片来源网络,侵删)
- 技术手段:
- 数据库直连: 通过 JDBC (Java), ODBC (Python, R) 等标准协议,直接连接到业务数据库(如 MySQL, Oracle, PostgreSQL)进行读取。
- ETL/ELT 工具: 使用专业的数据集成工具(如 Informatica, Talend, Fivetran, Airbyte)从业务系统抽取数据。
- 文件导出: 从 CRM, ERP 等系统中手动或定时导出 CSV, Excel, JSON 等文件。
- 特点: 数据结构化程度高、价值密度高、与核心业务流程紧密相关。
d. 第三方数据
- 技术手段: 通过购买或合作的方式获取。
- 数据服务商: 如尼尔森(市场研究)、艾瑞咨询(互联网数据)、Kaggle(竞赛数据集)。
- 政府/公共机构开放数据: 如国家数据共享交换平台、气象数据、交通数据等。
- 特点: 数据经过专业处理、质量高、但通常需要付费或遵循特定授权协议。
按采集方式划分
这决定了数据采集的主动性和实时性。
- 主动采集:
- 拉取: 系统主动向数据源发起请求获取数据,爬虫定时去抓取网页、客户端定期向服务器拉取更新。
- 特点: 实时性可控,但可能对源系统造成压力,且受限于对方是否开放接口。
- 被动采集:
- 推送: 数据源主动将数据推送给采集系统,用户提交表单、服务器日志实时写入消息队列、传感器数据上报。
- 特点: 实时性高,响应快,但需要数据源方配合。
- 同步采集:
程序发起请求后,一直等待直到数据返回,简单直接,但会阻塞主线程,不适合高并发和低延迟场景。
- 异步采集:
程序发起请求后不等待返回,继续执行其他任务,当数据到达时通过回调或事件机制处理,效率高,是现代系统设计的首选。
 (图片来源网络,侵删)
(图片来源网络,侵删)
按数据类型划分
- 结构化数据:
- 定义: 有固定格式和字段的数据,如关系型数据库中的表数据。
- 采集: 主要通过数据库连接、API 调用。
- 处理: 直接存入数据仓库或数据集市。
- 半结构化数据:
- 定义: 有一定结构但schema不固定的数据,如 JSON, XML, HTML, 日志文件。
- 采集: 主要通过爬虫、文件读取、API 解析。
- 处理: 需要通过解析器(如 JSON Parser)提取字段,再进行结构化处理。
- 非结构化数据:
- 定义: 没有固定格式的数据,如文本、图片、音频、视频。
- 采集: 通过爬虫抓取、摄像头/麦克风采集。
- 处理: 需要复杂的算法进行预处理和特征提取(如 NLP 处理文本、CV 处理图像)。
第二部分:数据采集系统设计
设计一个健壮、可扩展、高效的数据采集系统,需要遵循架构原则和设计模式。
系统设计核心原则
- 高可用性: 系统不能有单点故障,采集任务失败应有重试机制,服务组件应冗余部署。
- 可扩展性: 当数据量或采集任务增加时,系统能通过水平或垂直扩展来应对,微服务架构和消息队列是实现扩展性的关键。
- 低延迟/高吞吐: 根据业务需求,设计能快速处理数据或高并发处理数据的管道,流处理架构适合低延迟,批处理架构适合高吞吐。
- 数据质量与一致性: 采集的数据要准确、完整、一致,需要有数据校验、去重、清洗的环节。
- 可维护性与可观测性: 系统应易于监控、调试和运维,完善的日志、指标和链路追踪是必须的。
典型系统架构
一个现代的数据采集系统通常采用分层架构,将不同功能解耦。
+--------------------------------------------------+
| 数据源 |
|--------------------------------------------------|
| 业务数据库 | 日志文件 | 传感器 | API | 网页 |
+-----------------------+--------------------------+
|
+-----------------------v--------------------------+
| 采集与传输层 |
|--------------------------------------------------|
| 数据采集Agent | 爬虫 | CDC工具 | 消息队列 |
| (Fluentd, Logstash) | (Scrapy) | (Debezium) | (Kafka, Pulsar) |
+-----------------------+--------------------------+
|
+-----------------------v--------------------------+
| 数据处理与缓冲层 |
|--------------------------------------------------|
| 数据清洗 | 数据转换 | 数据格式化 | 临时存储 |
+-----------------------+--------------------------+
|
+-----------------------v--------------------------+
| 数据存储层 |
|--------------------------------------------------|
| 数据仓库 | 数据湖 | 时序数据库 | 搜索引擎 |
| (Snowflake, BigQuery) | (S3, ADLS) | (InfluxDB) | (Elasticsearch) |
+-----------------------+--------------------------+各层详解:
- 数据源层: 如前所述,各类数据产生的源头。
- 采集与传输层:
- Agent: 部署在数据源所在服务器上的轻量级程序,负责采集本地日志、数据库变更等,并转发到中心系统。
Filebeat(日志),Fluentd(通用),Telegraf(指标)。 - CDC (Change Data Capture): 专门用于捕获数据库的增、删、改操作,实现实时数据同步。
Debezium,Canal。 - 消息队列: 作为“缓冲”和“解耦”的核心,所有采集到的数据先统一发送到消息队列,再由下游消费者异步处理,这削峰填谷,提高了系统的弹性和可靠性。Kafka 是事实上的标准。
- Agent: 部署在数据源所在服务器上的轻量级程序,负责采集本地日志、数据库变更等,并转发到中心系统。
- 数据处理与缓冲层:
- 在数据正式入库前,进行清洗(去除空值、异常值)、转换(字段映射、类型转换)、富化(关联其他数据源信息)等操作。
- 这个层可以在数据写入存储前完成,也可以在存储后通过计算引擎(如 Spark, Flink)进行。
- 数据存储层:
- 数据仓库: 存储经过清洗、转换后的结构化数据,用于商业智能、报表和分析。
- 数据湖: 存储原始的、各种格式的数据(结构